⛏️ Scrapez vos données préférées - notre guide pour tous les niveaux

💎 Dans le monde merveilleux de la datavisualisation, tout est possible… tant qu’on a de la data. Dans le meilleur des cas, elle vous est fournie clé en main, mais le plus souvent, la donnée est devant vous, stockée sur un site web, noyée dans un océan d’informations variées et pas forcément toutes utiles. Il va donc falloir aller la chercher avec des techniques d’automatisation et, souvent, en sortant “le grattoir” (le “scraper” en bon anglais).
Défi : récupérer la liste des plus beaux projets de dataviz mondiaux 🤩
Depuis 2012, le concours des Information is Beautiful Awards récompense chaque année la crème de la datavisualisation mondiale. Une mine d’or pour se constituer une veille solide, alors collectons un maximum d’informations sur ces projets ! Laissez-vous guider étape par étape.
🛠️ Nous vous avons concocté un tutoriel en 3 niveaux de difficulté - et donc de performance - qui vous permettra de “gratter” de la donnée en pagaille.
🧑⚖️ Note : Le scraping de données n’est pas illégal en soi, mais devient problématique s’il viole les conditions d’utilisation d’un site, contourne des mesures de protection techniques ou porte sur des données personnelles. La légalité dépend du contexte : ce qui est scrapé, comment et dans quel but.

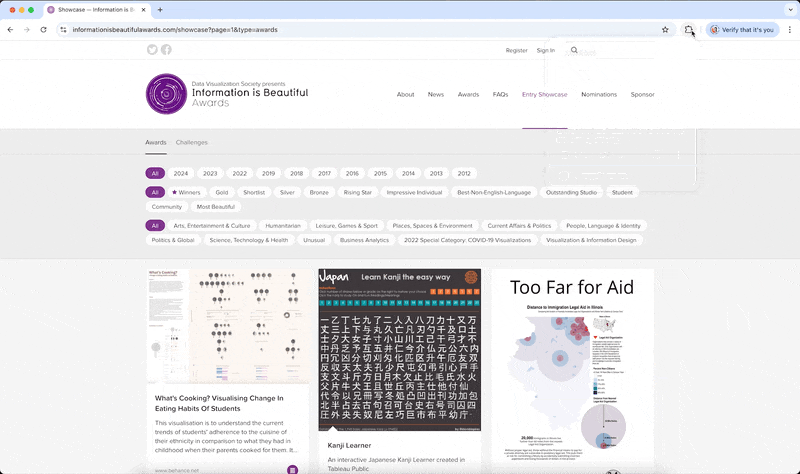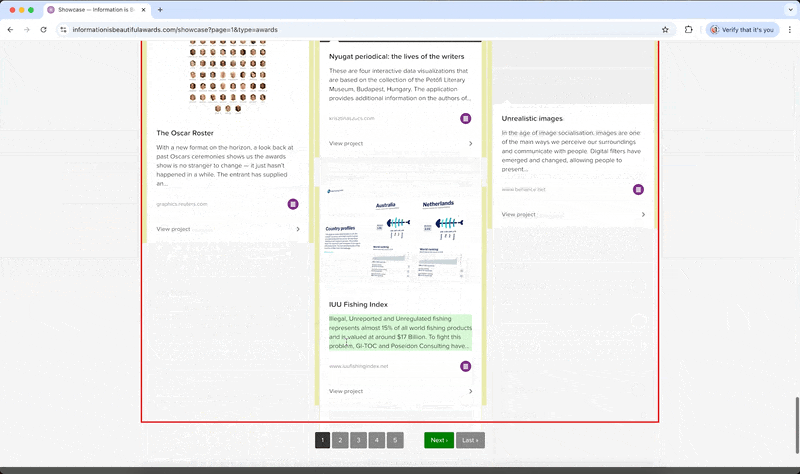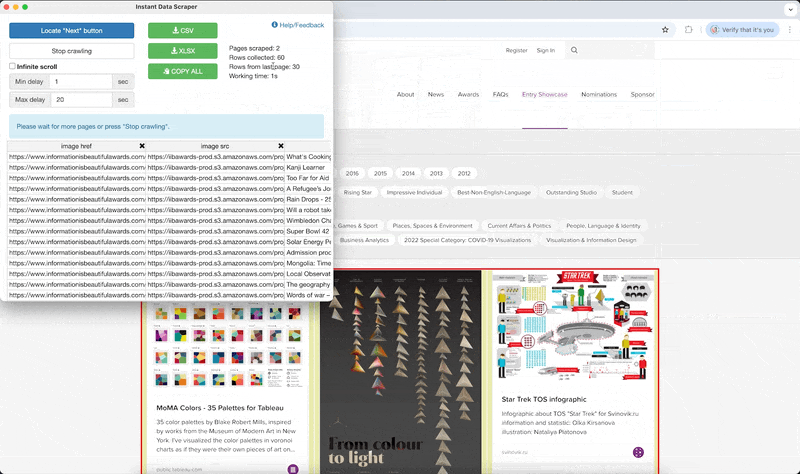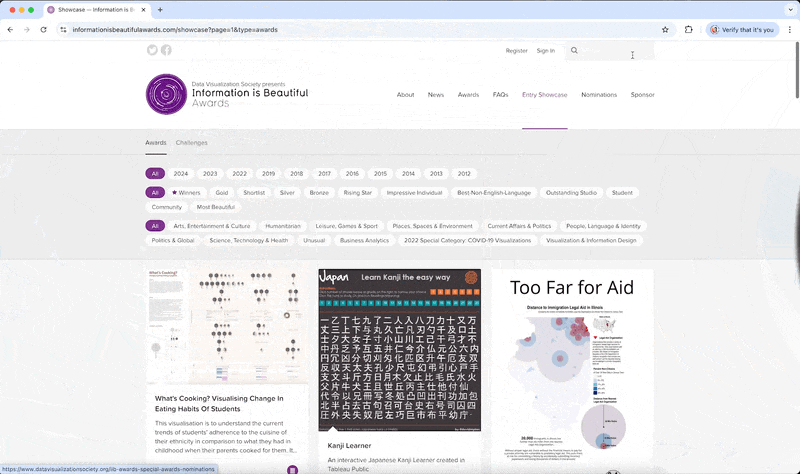
Instant Data Scraper est un plugin qui analyse la structure HTML d’une page web et identifie pour vous les données structurées et les balises. En un clic, vous pourrez donc “aspirer” toutes les données que vous souhaitez sur la page. Bonus : Instant Data Scraper permet de naviguer à travers des pages numérotées et de récupérer ainsi de grandes masses de données.
Comment scraper ?
- Installez le plugin dans votre navigateur, Firefox, Edge ou Chrome/Arc.
- Rendez vous sur la page des “Information is Beautiful Awards” (IIBA), sélectionnez tous les projets en cliquant sur “All” pour tous les filtres, puis lancez le plugin (dans un souci de “légèreté”, nous avons fait tourner notre tutoriel sur 2024 seulement).
- Si tout se passe bien, une table apparaît avec les données que vous recherchez bien rangées. Ici, vous verrez apparaitre le lien de l’image, le titre du projet, la description, le lien vers le projet ou encore les icônes qui préfigurent des catégories du projet. NB: Si vos données n’apparaissent pas directement, essayez le bouton “Try another table” pour voir si le plugin peut tenter d’extraire d’autres informations.
- Vos données sont-elles stockées dans un “catalogue” de plusieurs pages (c’est typiquement le cas ici) ? Utilisez la fonction “Locate ‘Next’ button” et indiquez au plugin où se trouve le bouton pour passer à la page suivante. Il pourra ainsi naviguer par lui-même de la première à la dernière page.
- Enfin, cliquez sur “Start crawling” pour lancer le scraping : vous verrez votre table se remplir au fur et à mesure que le plugin parcourt toutes les pages du site. Impressionnant, non ?
- Téléchargez votre belle base de données au format csv, ou xlsx.
Les +
- Très facile d’utilisation.
- Permet de naviguer rapidement dans des centaines de pages.
Les -
- Le plugin reste uniquement au niveau de la page scrapée et ne navigue pas DANS le site. Si toutes les infos ne sont pas présentes sur la page que vous scrapez, mais sont cachées dans des sous-pages, vous manquerez certaines informations. Dans notre cas, l’année du prix, une partie des catégories/récompenses du projet et la description longue ne sont disponibles que sur la page dédiée à chaque projet.
Si nous voulons récupérer des données moins ordonnées, ou que certaines informations sont cachées à différents niveaux hiérarchiques du site, d’autres outils s’imposent.

Lorsque vous visez une donnée très précise dans une page web, vous pouvez l’extraire simplement, toujours sans coder, à l’aide de Google Sheets et de sa fonction IMPORTXML() (nous vous dévoilions nos fonctions favorites dans une précédente édition). Attention, ce deuxième niveau de difficulté vous amènera à plonger dans la profondeur du code HTML de la page et son lot de balises XML.
Comment scraper ?
- Importez dans Google Sheets les données des projets nommés aux IIBA que vous avez obtenues à la fin du Niveau 1. Nous allons utiliser le champ de l’URL de chacune des fiches projet pour aller chercher un certain nombre d’informations à l’intérieur.
- Dans une nouvelle colonne, insérez la formule suivante : =IMPORTXML(A2;"xpath"). A2 fait référence à la cellule où se trouve la première URL, le xpath correspond au chemin d’accès en XML qui mène à l’information que vous souhaitez extraire.
- Mais où trouver ce fameux et nébuleux xpath ? Attention, ça se complique : Rendez-vous sur la page d’un projet (par exemple celle-ci), ouvrez l’inspecteur (Ctrl+Maj+I ou Cmd+Option+C) et explorer le code à l’aide de l’outil Select. A tâtons, en cliquant sur l’élément que vous souhaitez identifier, vous devriez réussir à le localiser dans le code HTML qui s’affiche à droite. Vous pouvez alors copier son xpath à l’aide d’un clic-droit > Copier > Copier le XPath.
- Collez le xpath dans la formule IMPORTXML() précédemment créée. Attention aux guillemets doubles qu’il faut convertir en simples (’root’ au lieu de “root”). Vous pourrez retrouver le bon xpath dans les cellules G3 pour l’année et H3 à L3 pour les tags.
- Observez la magie se produire et les catégories apparaître ! Vous pouvez dupliquer la formule sur toute la colonne… Tiens, certaines cellules semblent ne pas se charger, il va falloir passer au niveau 3.
Les +
- Une solution no-code, relativement facile d’accès.
- Remplissage directement dans votre base de données.
Les -
- Creuser dans le code HTML est fastidieux, mais malheureusement indispensable pour le scraping.
- Le nombre d’appels à IMPORTXML() est limité dans une même feuille et vous aurez des erreurs pour des grandes bases de données.
Si vous avez plus d’une cinquantaine d’URL à scraper, vous serez bloqués par le nombre maximum de requêtes… Dans ce cas, passer par du code s’imposera.

Si le code ne vous fait pas peur, la solution la plus performante - mais aussi la plus complexe - pour scraper des données reste l’utilisation de Python. L’une des librairies les plus utiles pour cela est BeautifulSoup, car elle permet de charger le code HTML d’une page et de l’explorer pour extraire les informations voulues. Pour vous mettre le pied à l’étrier et vous faciliter la tâche, nous avons mis sur pied un script sur Google Colab. L’avantage ? C’est collaboratif et vous n’avez pas à installer ni à configurer les librairies sur votre machine.
Comment scraper ?
On repart ici de zéro, sans utiliser les tableaux déjà obtenus aux deux premières étapes. On va parcourir tout notre site via Python.
- Importez les librairies requests et BeautifulSoup
- Identifiez dans le code de la page (ou à la main) le nombre de pages à parcourir et mettez en place une boucle pour parcourir toutes les pages
- Pour chacune des pages du “catalogue”, vous allez devoir identifier dans le code HTML les balises qui encapsulent l’URL des pages projet, puis boucler dans chacune de ces pages pour obtenir les informations que l’on recherche.
- Sur l’une des pages projets, repérez les balises HTML qui contiennent les informations que nous souhaitons récupérer : catégories (tags), édition des IIBA, texte complet…
- Vous constituez ainsi votre base de données complète et exhaustive des informations. Bravo !
Les +
- Très flexible, on peut - plus ou moins - tout récupérer et en grande quantité.
Les -
- Demande des compétences un peu poussées en Python… et un peu en HTML.
- Génial tant que le site est “statique”, mais ce n’est pas adapté pour des sites qui reposent sur des interactions utilisateur·rice·s ou qui sont dynamiques car codés en javascript par exemple.
Retrouvez ici la base intégrale des projets nommés aux “Information is Beautiful Awards” depuis 2012 :
POUR ALLER PLUS LOIN
- Pour les sites dynamiques, en javascript : vous aurez parfois besoin de simuler une navigation web et donc d’utiliser Selenium.
- Avec de l’IA ? Vous pouvez utiliser un LLM pour extraire du contenu d’un code HTML (attention aux hallucinations tout de même). Cette vidéo de Productive Dude vous montre un exemple d’utilisation de n8n et de ChatGPT pour scraper n’importe quel site, notamment des données non structurées 🔥🔥🔥.